Text Encoding
提要
- 你知道處理亂碼問題嗎?
- 文字如何儲存成 二進制的位元組? ASCII Table
- 多位元字符集 Multi-Bytes Characters
- Linux Command Tools :
iconv,hexdump - Common Encodings (UTF-8 / UTF-16 / Big-5 / GB-2312 / LE / BE / BOM)
文字如何儲存成檔案
Text vs Binary File
檔案基本可以分成兩種
- Text File 儲存內容 bytes 經過 某種編碼 轉換,可以翻譯成 字符(文字),如
txt,xml,json - Binary File 儲存二進制,需要使用特定軟體解析格式,才可使用,如
jpeg,mp3,doc,xls
這裡討論的是 Text File 的編碼 (Encoding)
ASCII Table
- 1963 年發佈第一版的標準 ASCII Table,全名為
AmericanStandardCode forInformationInterchange. - 使用 7 bits (2^7), 從 0 ~ 127 共定義了 128 個字符
- 33 個不可見的控制字元,如 斷行,響鈴 (0~31, 127);多數現今已沒有用處。例如 響鈴 :
echo -n -e '\x07' - 95 個可顯示的字元
-
延伸字集,Extended ASCII,使用 8 bits (2^8),多定義了 128 個字符,如
Ä â Ç ¬ ©。加入了一些歐洲語言字母。 - 電腦螢幕最早只能顯示寬 80 x 高 24 個文字
- ASCII Art
上世紀 80 年代左右,許多人熱衷利用 ASCII 定義的字符,進行 80 x 24 的繪畫

斷行符號 (New Line)
常見的斷行符號 (New Line) 有三種
Abbr. Hex Dec Escape 常見於
LF 0A 10 \n Linux, MacOS, Unix
CR LF 0D 0A 13 10 \r\n Windows
CR 0D 13 \r 早期蘋果電腦
Multibyte Characters (Wide Characters)
為了處理 EASCII 沒有的文字,如 中文,日文,阿拉伯文…,各國開始自行定義了各國的編碼,在 2000 年前後,各種國家編碼如:
BIG5: 繁體中文,常見於 台灣,香港GB2312: 簡體中文GB18030: 簡體中文,韓文,日文。中華人民共和國給予 GB2312 編碼再拓展而成。SHIFT_JIS: 日文
亂碼!

各國編碼互不相通,如果有一個 text 文件中需要同時出現 阿拉伯文,日文,中文,就不能使用以上的編碼;隨著互聯網打破國際的侷限,亂碼問題開始頻繁出現。
Unicode
1991 年開始發佈的 Unicode 萬國碼,定義各國語言字符對應的編碼。 目前最新的版本為 2021 年 9 月公布的 14.0.0,收錄超過 14 萬個字元。
依據 Unicode 編碼的實現,常見的有:
- UTF-8 : 使用 1 ~ 4 個 bytes 表示一個字符
- UTF-16 : 使用 2 or 4 個 bytes 表示一個字符
輔助的 linux 指令工具
- windows 可以安裝 cygwin,就可以使用 linux 指令。(安裝時候請加選上組件 : iconvlib)
iconv轉換編碼的工具hexdump輸出二進制編碼echo輸出字符
# 列出支援的編碼列表
iconv -l
# 將編碼從 BIG5 轉換為 UTF-8
iconv -f BIG5 -t UTF-8
# 輸出 abc,然後利用 pip '|' 傳給 hexdump 查看二進制
echo 'abc' | hexdump
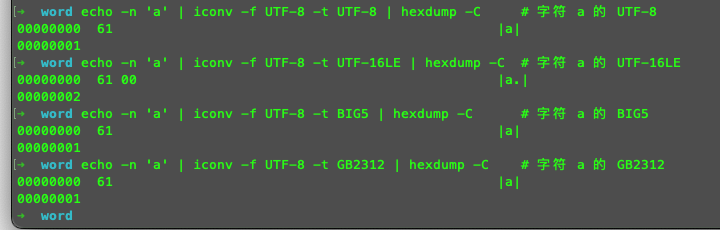
觀察字符 a 的編碼
echo -n 'a' | iconv -f UTF-8 -t UTF-8 | hexdump -C # 字符 a 的 UTF-8
echo -n 'a' | iconv -f UTF-8 -t UTF-16LE | hexdump -C # 字符 a 的 UTF-16LE
echo -n 'a' | iconv -f UTF-8 -t BIG5 | hexdump -C # 字符 a 的 BIG5
echo -n 'a' | iconv -f UTF-8 -t GB2312 | hexdump -C # 字符 a 的 GB2312
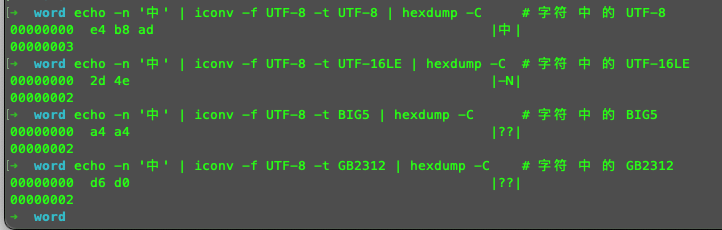
觀察字符 中 的編碼
echo -n '中' | iconv -f UTF-8 -t UTF-8 | hexdump -C # 字符 中 的 UTF-8
echo -n '中' | iconv -f UTF-8 -t UTF-16LE | hexdump -C # 字符 中 的 UTF-16LE
echo -n '中' | iconv -f UTF-8 -t BIG5 | hexdump -C # 字符 中 的 BIG5
echo -n '中' | iconv -f UTF-8 -t GB2312 | hexdump -C # 字符 中 的 GB2312
其他細節 BE / LE / BOM
中 字的 unicode 編碼是 2D, 4E 兩個 bytes, 那麼應該儲存成 2D 4E 或是 4E 2D 呢?
因為電腦業界一開始並無規範,各家有各家的作法,後來以 BE (BigEndian) / LE (LittleEndian) 來表達這個爭議。
Gulliver’s Travels
遊記中,格列佛來到小人國,小人國發生內戰,原因是關於吃雞蛋,一派人堅持從 大頭 Big End 打開來吃,而國王堅持要從 小頭 Little End 開來吃。因此將兩派人成為 Big Endian / Little Endian。
近代的 Windows / Linux / MacOSx 都已經採用 LE。早期 PowerPC / Solaris / AIX 主機使用 BE。

- Big Endian / Little Endian

那麼如何知道 UTF-16 的文件是使用 LE 或 BE 進行儲存?
有些文件一開始會用 幾個 bytes 表達,這幾個 bytes 就稱為 BOM (Byte Order Mark)
- UTF-16 BE 的 BOM 是 2 個 bytes :
0xFF 0xFE - UTF-16 LE 的 BOM 是 2 個 bytes :
0xFE 0xFF - UTF-8 的 BOM 是 3 個 bytes :
0xEF 0xBB 0xBF其實 UTF-8 文件不需要 BOM,但有些會有。
最後
- 掌握以上知識,能夠解決
亂碼問題。 - 每個工程師都應該有工具讓自己查看檔案的二進制內容。
iconv指令可以幫你轉換各種格式的編碼。Linux / MacOSX 系統本身自帶。